Archive of posts with tag 'programming'
Feb 2015: Principles of Determining Geolocation
In 2004-2005, I worked for Quova as a Network Geography Analyst.
As a practical matter, given that MLB was one of our largest customers at the time, this meant that we fielded complaints for people who were locked out of viewing baseball games where they should not have been, and a good chunk of my job was investigating those complaints.
This is intended for a mixed-level audience, so I’m going to skip deep nuance and detail. ## Simple Explanation
- When you connect to the internet, whether through cable, your cell phone, whatever, you’re assigned an IP address, where IP stands for Internet Protocol. At the point in time you connect, your IP address has a fixed location in physical space: wherever you happen to be.
- Your device connects to another, upstream device, and depending upon where you want to go, it connects to a series of other devices until it arrives at your intended destination (say, Google’s web server). Each of those devices has an IP address, and each of those IP addresses has a fixed location in physical space.
-
If you ask for a traceroute from a command line, it’ll tell you what series of hops it goes through to get from point A (you) to point B (where you want to go).
$ traceroute 8.8.8.8
traceroute to 8.8.8.8 (8.8.8.8), 64 hops max, 52 byte packets- 10.0.1.1 (10.0.1.1) 10.938 ms 1.183 ms 1.032 ms
- 198.144.195.185 (198.144.195.185) 51.874 ms 52.194 ms 51.948 ms
- ge1-8.rawbw-demarc.sfo4.reliablehosting.com (216.131.94.209) 61.865 ms 57.246 ms 64.077 ms
- core2-1-1-0.pao.net.google.com (198.32.176.31) 52.671 ms 51.958 ms 55.120 ms
- 64.233.175.169 (64.233.175.169) 56.400 ms
64.233.175.171 (64.233.175.171) 54.772 ms
72.14.236.114 (72.14.236.114) 54.420 ms - google-public-dns-a.google.com (8.8.8.8) 54.663 ms 54.480 ms 94.454 ms
The first is my internal IP address. The second is our gateway address. The third is our provider’s demarc with their upstream. The fourth is where it enters Google’s servers.
- Network administrators, to make their lives easier, often label those intermediary hops with names. This is not required. Often those names have geocoding information. These are often names of cities, airport codes, weather station codes, neighborhood names, apartment complex names—all kinds of things. In core2-1-1-0.pao.net.google.com, “pao” is Palo Alto, California, which has an airport IATA code of PAO.
- If you’re very lucky, you will have a traceroute that shows very little router delay (like one hop in my example above). Then you can use actual physics to tell you where it must be in relation to the adjacent hop.
Light (and electricity) travels 300,000 km/sec, or 186,000 miles/sec. Per millisecond, 300 km or 186 miles. It’s easier to multiply by 300 than 186 in my head, so I’ve typically stayed metric at this point, but I’ll give both. Besides, it just sounds cool to drop millilightseconds in a conversation.
See that last hop? 54.420 -> 54.480 (using minimum to minimum)? That’s 6 hundredths of a millisecond, meaning the laws of physics say the packet traveled a maximum of 18 km or 11.2 miles.
Except traceroute measures time there and back, so the real numbers are 9 km or 5.6 miles.
Is it in Palo Alto? The end location is 1.808 ms from the stated Palo Alto location, which means it’s at most 262.35 km or 168.25 miles from Palo Alto. So almost certainly SF Bay Metro with some lag. This is where repetitive traceroutes at different times from different locations would be helpful. (I’d expect the location to be Mountain View, California, which is the city south of Palo Alto, and also Google’s HQ.)
That’s the Basics. Really.
So the real trick to geolocation is to have as many knowns as possible. This means having server space on fast networks around the world, being able to triangulate in on locations of interest, and getting different results over time.
You can read more about using millilightseconds in this humorous story of network diagnosis.
This four-part series about traceroute is quite good, and covers some of the wrinkles.
My Own Little Experience
I mentioned this on Twitter at the time it happened.
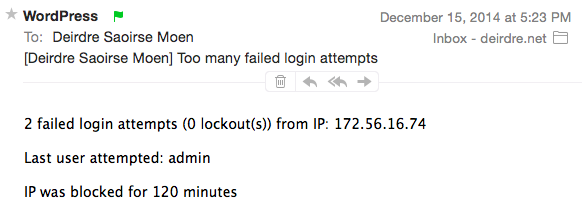
There are some interesting nuances here:
- I don’t have a user called admin, but that’s the default super user in WordPress.
- If you do a whois on that IP address, you’ll note it’s assigned to T-Mobile:
NetRange: 172.32.0.0 – 172.63.255.255
CIDR: 172.32.0.0/11
NetName: TMO9
[…]
Organization: T-Mobile USA, Inc. (TMOBI)
Real hackers trying to crack into your web site will not be using mobile as a rule. This was personal, not a doorknocker. - At the time, it showed up as being in LA. Once you get a dynamically-assigned IP address, such as a mobile address, to a metro area, there’s no guarantee you’ll get closer than that.
-
[I note that this screenshot shows 1) T-Mo; 2) LA](https://twitter.com/jaidblack/status/461945958104698881), and my breakin attempt was [a couple of hours after this was posted](https://deirdre.net/elloras-cave-trust-and-confidence-wtf/). Obviously, no proof, yada yada. Just: correlation.
Update to this section, May 2015: It turns out, and I’m thankful for this, that there is a far more ordinary explanation for what happened. I can’t prove it’s what happened in December, but it did happen last week. In January 2014, Rick and I were traveling and would be in some of the remotest parts of the world (in fact, we spent three days out of satellite range of Internet, believe it or not). I gave admin credentials to a friend who lives in the LA area to blogsit and make sure any security updates got applied while we were gone. It turns out that, since saving that password, she’d switched her mobile device from Verizon to T-Mobile, and I’d since changed the admin username. She doesn’t use mobile data much, so it didn’t try to access my site for a long time (or frequently). And there you are.
My apologies to Jaid Black for the insinuation.
Also, a better security method for dealing with this issue is to make a second admin user. Doh.
Quick Geolocation for Mere Mortals
Nov 2014: Geek Humor
QA Engineer walks into a bar. Orders a beer. Orders 0 beers. Orders 999999999 beers. Orders a lizard. Orders -1 beers. Orders a sfdeljknesv.
— Bill Sempf (@sempf) September 23, 2014
@sempf was it a mock bar?
— Brian H Prince (@brianhprince) September 23, 2014
@sempf You forgot about when he ordered 0’; DROP TABLE BEERS;
— Adrian Petrescu (@apetresc) September 23, 2014
@sempf @joshbillions Ah yes, the Edge Case Saloon. A fine establishment.
— Bill Van Loo (@billvanlooteach) September 23, 2014
@sempf A QA egineer walks into a bar. orԁèrs å bëer
— sheila miguez (@codersquid) September 23, 2014
@sempf @marxculture add ‘tries to break the beer tap’, ensures that the liquid coming from the beer tap is in fact, beer.
— Paul Walsh (@Paul__Walsh) September 23, 2014
@sempf Orders a bier. Orders a cerveza. Orders a pivo. Orders a cerveja. Orders a pia. Orders a øl. Orders a ເບຍ. Orders a 啤酒.
— Aleksis Tulonen (@al3ksis) September 23, 2014
@sempf @therealfitz Response from our QA expert: pic.twitter.com/W6ejEYueMU
— Jenna Bilotta (@jenna) September 23, 2014
@sempf Quickly orders a second beer before the first is served.
— Brian Ott (@botticus) September 23, 2014
@sempf Bartender pours one beer and says “Works on my machine”
— Chris McMahon (@chris_mcmahon) September 23, 2014
@sempf pentester orders <script>alert(1);</script> beers 😉
— Simon Bennetts (@psiinon) September 23, 2014
@sempf Sample code walks into a bar. But only after walking into a foo.
— mbklein (@mbklein) September 23, 2014
. @sempf Meanwhile, her security researcher friend bypasses the bartender, pours <img src=x onerror=alert(‘xss’) /> beers for someone else.
— James Roper (@jroper) September 24, 2014
@sempf @OzIndie you forgot: QA Engineer orders a beer, walks into a bar.
— Rossy (@SudoRossy) September 24, 2014
May 2014: The Seventies: Getting into Programming
Note: this is part of a much longer piece I’m writing, which I’ll announce later. I thought you’d enjoy this first draft excerpt.
I took my first programming class in the summer of 1975; I was 15 when I started. The programming lab was in the math and science building of Saddleback College. Back in those days, they had a Data General Nova 3 minicomputer with 64K of core memory (not RAM) and 64K of floating point core. Now, those of you who’ve never seen core memory, each bit is a magnet on a larger lattice framework and 64k of core took up a significant amount of space, though what we had, both floating point and regular memory, probably fit into less space than that photo I linked to.
Saddleback’s Nova did have a hard drive that was about the size of a washing machine, with one fixed platter set and one removable one. I don’t remember exactly how much drive space it had, but let’s just say it was a handful of megabytes.
I grew fascinated with the computer lab. The smell of the oil on the paper tape drives, the sound of the hard drives seeking, the gentle clicking of other switches and relays, the drama when the multiplexer melted over 4th of July weekend. I loved every bit of it.
My dad had said, “You like puzzles, you’re good at math. You’d be great at this, and you might actually enjoy it.” Back then, programming wasn’t a big industry, so he didn’t actually expect it to be a field I’d really go into. It was more one of those parental “hey, check it out” things.
At the time, I was extremely shy, and screwing up in front of other people, or where other people could watch, was my least favorite thing ever.
So, even though I considered it impersonal, that was precisely why programming worked for me. If I couldn’t figure something out right away, the computer would tell me I was wrong and I’d suffer in silence. I’d work at different approaches to the problem until I understood it well enough that I’d have the solution worked out.
Because of my immersion into computers and programming, when there was an opening for a lab assistant the next term, I was offered the position, and accepted. I learned more about the Nova minicomputers and read the entire thick manual on operating it, trying to understand the relationship between assembler (which I had not yet taken, but could read through simpler bits of) and the binary it translated into.
The minicomputer took up about half a rack, and its hard drives cabinets were about the size of a modern washing machine. The entire thing needed enough power that it had to have a raised subfloor, quite common in computer rooms of the day.
When booting the Nova every morning when the lab opened, someone had to hand-check the paper tape driver in binary using the front panel switches. Now, one of the beauties of core memory is that it’s non-volatile, so that usually translated to three things: 1) checking that the sequence was still correctly in memory, fixing it if necessary; 2) going to the memory address where the driver started, then 3) start the system running from there. Eventually, I memorized it enough that I could check the entire sequence without thinking. It just became a familiar pattern of numbers.
Saddleback offered a single class in Basic programming (that everyone took first) plus one in Assembler and another in Fortran. All three were taught through the Math department. You had to do the lab work for Fortran at UC Irvine, which was about 15 miles away. The fourth class offered, Cobol, was taught through the Business department, and you had to do the lab work at Cal State Fullerton. This was the one class I never took, though.
That’s it. Four total classes, plus any independent study opportunities.
At the time, there were zero Computer Science degree programs in the United States, so far as I knew. You could get an Engineering degree with a Computer emphasis (EECS), or a Math degree, or a Business degree, but no standalone degree in Computer Science that wasn’t primarily about another discipline. That had yet to be invented.
So if this happened to be your thing, as it was mine, it was a tough field to enter back in 1975. You didn’t really learn enough at the community college level to do it full time in industry, but how else would you learn enough? The four-year programs weren’t much better.
These days, you’d buy a computer and work from home on various projects, perhaps open source ones.
Back then, a computer cost on the order of a year’s rent (at least by the time you got enough doohickeys to make it actually useful for anything) and required being soldered together. Of course, this was the kind of project that friends would help you with. In fact, four of us did exactly this for my high school physics project the following year. Having helped my father solder together the parts on a Heathkit oscilloscope, I did an awful lot of the soldering on that project.
Effectively, the price and difficulty barriers meant no one had a computer at home in that era. Computers like the original Apple I were just starting to become available.
One day, the lab got a request for a job interview from a local business, BasicFour, headquartered on the Irvine/Costa Mesa border near South Coast Plaza. They’d asked to interview a more senior lab assistant. He was 17, had a few months more experience than I did, but he’d also recently accepted a job offer.
The lab manager handed the information to me and said, “This could be a great opportunity for you.”
I called and got an in person interview. I was so excited that it wasn’t until after I’d gone home that I realized no one had asked me any programming questions. I was given a tour and offered an alternate, lesser position.
“Normally we start women out in a data entry position,” the man in the suit said. It paid less than half as much money. Since data entry positions have largely gone away—the position was for a glorified typist, still very much considered “women’s work” at that time. If nothing else good ever came of the Internet, at least women don’t have to put up with men feigning being too good to type their own crap.
I turned it down, but gave no reason.
Dejected, I almost didn’t go back to the Saddleback lab the next day. I considered calling in sick. When I did go in, I reluctantly walked over to my boss’s office.
“How’d it go?” she asked.
I told her what they’d said, then I told her that I’d turned them down.
“Good,” she said. “They shouldn’t have done that.” She asked me what I wanted to do, ensuring that I knew that I could report what they’d said.
“Find a job with a company that treats people better.”
“Good idea,” she said, then said she wouldn’t be sending anyone else to interview there. Ever.
At that time, I wasn’t willing to write off BasicFour, even though I probably should have. They were a local employer. They gave me an interview. It didn’t matter that they screwed up so badly. I figured—perhaps correctly, perhaps not—that they may change their minds later. Given limited opportunities at the time, I didn’t want to alienate them. It hadn’t occurred to me then, but would now, that some of the people in charge of that policy would later become involved in other local ventures, so that was probably a wise choice. Unfortunate that I had to even think about that, then or now.
I was sixteen years old, I hadn’t even had a programming job yet apart from some work I’d done for my father, and I was already worried about being blacklisted.
Heck of a way to start a career.
{kind=link}
Apr 2014: Writing and the Critical Path
As someone who’s spent my whole life working mostly on one large project after another, you’d think novels wouldn’t be as hard for me to write as they actually are.
I had this glimpse into why: I generally had a sense, at all times, whether something was on the critical path—or not. There were desired features and planned expansions, but building them wasn’t part of my initial task. So there were clearly things on the critical path—and not. Generally, there was at least something of an order: I need to get pretty far along in X before I can test Y, so let’s write X first. I can work on Y if I’m stumped on X.
In a novel, generally all of the planned scenes need to be written because they’re interwoven. It’s all on the critical path.
Non-fiction’s different: some items may be optional. If they’re not written for the book itself, they can be re-used in other ways, like website content or newsletter content.
So I don’t necessarily have a sense of what I should work on next. The list is too large. Since I write out of order frequently that makes the problem set too large.
I’m going to have to think about this.
Apr 2014: Box.com: Using My Powers for Good
Four months ago, I posted this commentary and critique of Box’s “Working at Box” page.
It got back to me that it created quite a stir, but I hadn’t checked back on the page recently. I have noticed incoming links to that blog post, so I wondered what was up.
Credit where due, Box has revised the underlying page.
Thank you! Nice improvement.
Mar 2014: The Sort Implementation Interview Question
I’m going to go out on what seems to be a wildly unpopular limb here and say this: asking a developer to write an implementation of a sort algorithm is almost certainly a bad job interview question.
Why? Because you’re likely not hiring someone to write implementations of sort algorithms. Even if you were, they probably would not be writing optimized code in a job interview situation, so what’s it really testing?
Problem solving skills aren’t universal, nor does the ability/inability or inclination/disinclination to solve one kind of problem necessarily reflect one’s overall skills. Or lack thereof.
Remember that the person being interviewed is also interviewing you and deciding whether they want to work with you or not. If you ask a coding question that’s more directly relevant to the job at hand, then they will have a better sense of what it is you do every day—and whether that’s something they want to do, too. You’re engaging them in your problem space, not asking something they may or may not warm to even if they’d love the job you’re interviewing for.
For example, in an interview I went on once upon a time, the interviewer said, “We have this problem, and I’d like to see how you approach it.” So it was a supportive, shared, coding question. I had questions about some aspects of the requirements, which the interviewer then answered. That was a great interview approach.
I’ve come to dread the sort interview questions. Frankly, it’s not a part of programming I enjoy. I like the fact that other people think about sort implementations. Yay, diversity.
I remember once, I think it was 2005, having re-reviewed all the common sort algorithms, then flown to a job interview. The question: “How would you write a shuffle algorithm?”
I remember that instant of total frustration far more than anything else from the interview.
My answer was something like: create a hash of something like a random seed from the current time plus some aspect of the information you had about the song (since it was about shuffling songs) like the title, and then sort the hashes. I have no idea if that’s a good answer, but it’s what I came up with at the time.
Meanwhile, I’d much rather focus on whether we need this column or not, whether that schema is better suited for the project than this other one (and why), can we produce the desired page with less HTML/CSS markup? And how much can/should we shunt off to JavaScript? How much jQuery do we need? Does this page degrade gracefully without JavaScript? What pieces of this should go in the controller vs. the model or the view (and why)?
Using a different field, asking someone who’s applying for a general application programmer to write a sort implementation is like interviewing for a job as a Cosmo article writer and being asked to produce a sonnet in the job interview. (With the added bonus of live critique questioning your choices.)
Now that’s not to say that knowing how to write sonnets isn’t a cool skill. It is.
But let’s look at what an article writer needs skill at that a sonnet writer doesn’t:
- Ability to write whole sentences
- On time
- Correct length (sonnets have a lines/syllable count, but what an article writer needs is correct amount of space on the page, which is an entirely different form of length requirement)
- On correct subject
- Supports advertisers
- Current and relevant
- Literal language
What skills a sonnet writer needs that an article writer doesn’t:
- A feel for syllables
- Exhaustive vocabulary (because poetry readers will look up words but Cosmo readers almost certainly won’t)
- How to write something timeless
- The ability to fiddle until it’s “just so”
- Metaphorical language
99.9% of all people making their living as writers aren’t writing poetry. 99.9% of the rest write greeting cards for money. The other two are poetry professors. Random aside: did you know Cupertino has a poet laureate?
99.9% of all software engineers making a living as such aren’t writing implementations of sort algorithms or developing new sort algorithms as their job.
Ask more relevant questions.
Jan 2014: On Quark XPress's Demise
Back in the day, I used to write Quark XPress XTensions for a living, so this commentary (and linked article) about Quark XPress’s demise was fascinating.
One of those involved revamping and revising a significant (and sluggish) XTension to add new features.
I remember contacting Quark because of a problem we were having with so many boxes being laid out on the page (the XTension was for television listings, so there were often 600+).
They said, and I quote:
But why would you want to do that?
So I explained it to them, and they said:
Huh.
Here’s the thing. No matter what kind of program you write, someone will use it (or want to use it) in ways you don’t expect. You can learn to roll with that, or you can ignore it.
They chose to ignore it, as they chose with other customers.
And that is why oh so many of us no longer write Quark XTensions.
Dec 2013: Why I Wrote the Calcumatic
Bonjour to all my Francophone visitors!
A French site has linked to my E-Book Royalty Calcumatic, and there are a couple of points I wanted to address.
First, it is US-based, and it is my intention to expand it to other regions and vendors. It’s not my intent to be exhaustive, though.
One of the comments on the above link says (Original in French first, then a rough translation):
Etant donné que les ventes sont imprévisibles et aléatoires, ça en fait un outil complétement inutile!
Given that sales are unpredictable and random, that makes this tool completely useless!
Okay, it’s a fair point. Let’s look at why I did write it and get back to what it does and doesn’t mean.
There were a few reasons I wrote the tool the way I did (remember, I first wrote it in 2011):
- I worked on the Safari team at Apple and there was a cool new input element—range sliders—in HTML5. Every new toy must have a use case, right? This was mine. (I’d really love to have a pie chart slice draggy thing, honestly, but I’m not going to write one.)
- I wanted to convince some friends not to leave money on the table. Specifically, as someone who uses the Kindle format as my “last resort” choice, I wanted to convince them not to leave my money on the table. To this day, some people still only publish through Kindle’s program. Look, I get that there are compelling reasons for introducing books through Kindle’s store and giving them a 90-day exclusive. Truly I do.
- I figured I might actually educate some people who were readers, not writers—people who might think to take that extra moment to get the book from a different source that pays the authors better next time they were purchasing a book and had a choice of vendors.
However, there are always things you can’t control, right?
- You can’t control whether someone buys your book. Or not.
- You can’t control where someone buys your book (unless you sell it only in one place, which is a poor choice).
There are things you have some control over, though.
- You can put your book in multiple bookstores.
- You can preferentially feature stores that offer you better deals on your website. You don’t have to list Amazon first. (Yeah, I used to work at Apple, but this is just me being me, not me being an Apple alumna.)
See, I read in iBooks. I only read in iBooks.
Why? I think the layout and rendering is the best there. I like Apple’s choice of fonts. Iowan/Night theme gal, here. I like having all my books together in one big happy library.
I have a handful of Nook books. They are now in iBooks. I have a handful of Kindle books. They are ignored.
If you want me to purchase and read your book, you’ll put it somewhere in an EPUB. It’ll be available without DRM or it’ll be available in the iBooks store.
I don’t mind going to Smashwords to buy your books if I know they are DRM free. Heck, I’ll buy them off your website if I want to read the book and you sell direct. It doesn’t cost me anything extra, but you get paid faster and more money. Sounds like a win win to me.
Just don’t send me to the Kindle store, because you’ll lose the sale. Well, unless you write something so spectacular (like QF32) that I can’t resist buying the book. Still haven’t read it, though. But—you go ahead and land the biggest passenger airplane after an engine blows out and I’ll go to the Kindle store to buy your book, okay?
For years, I didn’t read The Hunger Games. Not available non-DRMed or on the iBooks store. Same thing with The Girl with the Dragon Tattoo when it was hot. I think we actually bought that one in paper—and Larsson’s heirs lost a few bucks accordingly.
I’m sure there are people equally fervent about their reading app of choice. Sell to them, too.
Dec 2013: Learning to Program and _why the lucky stiff
I still remember learning to program. I remember the yellow paper tape and the teletype machine. I remember the smell of machine oil on the paper tape. I remember the paper cuts.
What I can’t tell you is what I wanted to program back at that point in my life. Games, probably, which is something I’ve never done any significant amount of programming in.
At some point since then, I realized I could program pretty much anything I wanted. It’d run. It may not be beautiful. It may not be efficient. But I had the skill and experience (with any of a number of hammers in the form of programming languages) to pick an arguably appropriate tool, a reasonable approach to tackle the problem, and then commence kicking ass. No matter what the problem was.
I’m not easily intimidated by things I don’t know. I couldn’t have survived in this field if I were. I have cut a driver down to size to fit on a smaller EEPROM so it could go into space; I have developed power plant control systems to help reduce emissions; I have written commercial calendar software; I have written search and retrieval software; I’ve helped women schedule immunizations to avoid rH factor complications in pregnancy; I’ve written commercial audio track royalty management software; I’ve helped expand the TiVo service. Among other things.
What I forgot, somewhere along the way, is how hard the skills I have are to acquire, in part because I acquired them over a long period of time.
I’m used to arguing with computers. I’m used to that sheer frustration when things don’t go as expected, then the “Aha!” moment, followed by the endorphins of victory.
I was missing one of my favorite explainers of technology, _why the lucky stiff, the other day. I think of him often. In 2009, he suddenly deleted his online presence, then other people pieced much of it back together. However, the world is at a huge loss because he’s gone underground and chooses to remain there. This Slate article is both about his disappearance and about learning to program, and _why’s role in making learning to program easier.
Much as I hate to admit it, Slate author Annie Lowrey is correct: my personal favorite of _why’s resources, Why’s (Poignant) Guide to Ruby, probably is most accessible by people who already know how to program.
Frankly, I just like the Poignant Guide because, despite all my years of programming and all the books I’ve seen and read, this one is, hands down, the weirdest. Here are three bits out of it.
In one house, you may have a dad that represents Archie, a traveling salesman and skeleton collector. In another house, dad could represent Peter, a lion tamer with a great love for flannel.
Lately, the exchange rate has settled down between leaves and crystals.
Frankly, I’m sick and tired of hearing that Dr. Cham was a madman.
Not your typical boring programming book, right? I love the cartoons. (Chunky bacon!) I love the whole thing. It’s like The Imaginarium of Dr. Parnassus in programming language form.
But, then, I’m a programmer (by which I mean software engineer, though I’ve always preferred the term programmer because I almost always prefer shorter phrases with fewer syllables) who’s also a novelist. Unlike _why, I never tried mixing forms to the extent he has.
As the Slate article points out, a far more accessible way to learn to program is _why’s idea, fleshed out since his disappearance, Try Ruby. It’s still got the cartoon foxes, but, being interactive, it’s a little easier to understand. And a lot less weird.
_why, the world has been a more interesting — and better — place because of your brilliance, and I’d like to raise this toast:
5.times { print "Odelay!" }
“I just want to assure you that I’m trying to rid the world of people like me.” Some goals aren’t worth keeping.
Nov 2013: Making Book: A Technological Evolution
Once upon a time, I lost all the poetry I ever wrote, including the stuff I’d published. It was published in journals so small I’d be lucky if a single copy survives to this day. It’s possible dozens of people read my work.
Of all of those poems, I’m saddest about the piece I wrote the day I was in Belfast. The day we weren’t supposed to be in Belfast. The day I got a rifle pointed at me. (If you ever happen across Metropolis, a journal of urban poetry, with my poem titled “Belfast Brunch,” I’ll pay you for the copy.)
I thought: I’m a software engineer, why don’t I add all the stuff I’ve written into source control? But then you have two problems, as the old joke goes.
This was back in CVS days, and what CVS really didn’t like much was binary files. And me with a bunch of Word documents. Oh, and AppleWorks documents, because we know how forward-compatible those suckers are. (The current version of Apple’s Pages will not open them, but then it won’t open RTF, either.)
Novels and short stories don’t actually consist of a lot of sophisticated markup, though. There’s the occasional italics, the section breaks, the chapter headings. Because HTML was too much work to generate cleanly, I just wrote in plain text. With underlines around italics. You know, like Markdown. Though Markdown hadn’t been announced back then.
Eventually, I switched over to Subversion for source control. (I recently switched to git due in part to feedback on this post.)
However, getting stuff ready for critique or submission was another story entirely. I was talking about this with Serah Eley, and she mentioned using XSLT and XSL-FO, and had a perl/java toolchain that worked well enough, so I incorporated it into my own work. By this time, I was running my submissions through my own Ruby on Rails app, and it was slick enough that it knew where a project’s files lived, and would generate all the meta information needed by XSL-FO in order to make a PDF to print. (At that point, RTFs weren’t really possible as they were still the realm of proprietary software.)
So why XSL-FO? Part of it was the beauty of the templating system. You could make a stylesheet that specified double-spaced courier and to add an address block for a submission to an editor. You could make it single spaced in Garamond with no address block if it’s something you wanted to hand to someone you didn’t want to have your address. You could have a cover page and exclude your name on subsequent pages for contest submissions.
The downside, though is that XSLT is pretty fiddly and I had a toolchain from hell that required not only Ruby and Perl and Java, but a lot of dependencies that would occasionally drive me mad when they broke or balked.
And Then An Amazing Thing Happened
Apple decided to adopt EPUB for iBooks. Before that, there’d been a far more confusing array of choices for electronic formats, but then people started veering toward EPUB. Plus other tools had come out like calibre, which will convert your books (so long as you don’t mind it getting its grubby paws all over your markup and inserting its calibre-isms).
Then jugyo wrote eeepub, a ruby gem to make EPUB files. And, hey, I already had valid XML files from my earlier process, right?
Not long after that, I was the head of programming (by which I mean scheduling of people and rooms, not software engineering, though I also almost all of that, too) for BayCon and Westercon 64.
One of the things I wrote the code for was the generation of the tabular data for the program grid. From there, especially with jugyo’s excellent gem, it wasn’t that far to getting a program book in EPUB form. (Reusing work I’d done in 2003-2007, I was still using XSLT + XSL-FO + InDesign for things like table tents, back of badge stickers, room signs, and the schedule content for the body of the program book.)
I remember sitting down one night a few days before con, wondering if I could actually make an ebook version of the program schedule. I wrote it on too little sleep when I had a case of shingles, but hey, it works! PDF and EPUB versions of the file are linked on Westercon 64’s site. The PDF used the same intermediate XML that generated the EPUB, but I used InDesign to generate the final product.
Here’s the code to make the EPUB version. The tl;dr version of what it does:
- Figure out what days the convention runs. Get the names of those days.
- Calculate what public program items run, in order, and spit them out along with their program participants, one file per day. Make sure the program participants link to their bios. (Non-public items were things like meetings for exec staff and stuff we didn’t want to schedule against, e.g., when someone wasn’t planning to be in the masquerade but didn’t want to miss it.)
- Generate a file, in alphabetic order, of the program participants and their bios. Note: this file takes too long to render in the EPUB, and one of the changes I’d make if I were doing it again would be to break it up by first letter of last name or smaller groups to make the rendering faster.
- Commented out code used for Westercon: add the bylaws.
Simplifying the Novel-Production Process
Somewhere around 2008, Ruby had better Markdown support and I’d become aware that I was really writing drafts in Markdown, so I was able to eliminate part of the toolchain I had.
More recently, I discovered textutil, which does the back-end work I’d been using XSL-FO for. So, I can take an HTML file (which I get from Markdown) and get an RTF and a DOC and a PDF out of it? With almost no pain?
To quote Ben Grogan: I call that winning.
As the saying goes: now you have one problem.
General Casing the One Problem
I’ve been working on a more general case solution, both in Ruby and Python, for taking Markdown files and making a book out of them without having to do quite so much of the work.
I’ve tried a number of Markdown editors over the last couple of years, and I have standardized on ByWord on both Mac and iOS. For things that I’ve got in source control, I use git on Dropbox with my repository on BitBucket. I use a nightly script to push repository changes in case I forget to do so.
In my current process, I no longer have rails generate XML template files, nor do I need prose DTDs, etc. I just have rails generate a YAML file, and I’ve moved much of the configuration into the rails app. But now I need to push some of that back out into CSS. And maybe I want it to be a Cocoa app, you know?
I’m still thinking about ways to do that when I want to still be able to produce the following variants with no change of my Markdown files:
- Novel proposal, meaning synopsis (formatted one way) plus first three chapters or (as a programmer, I hate this one) no more than 50 pages.
- Novel chapter for critique, which usually means slightly different spacing and more whitespace for comments, but doesn’t need all the fancy fancy.
- Reading copy, which would be formatted pretty but not include author address (or legal name, necessarily).
- Final book format, which can include a lot more data than the above three, e.g., ISBN.
- Contest entry format which suppresses author name on pages other than the first. (Or, sometimes, at all, as it’s included only in a cover letter.)
- A relatively easy way to create variant style definitions and keep them together without requiring the rails app I’m currently using.
Most of that’s fairly easy, but some of it’s surprisingly subtle.
And here you thought I just flung words on pages.
Oct 2013: Writing Repositories: Git? SVN?
Apart from the fact that my writing process is complicated, the tech part of my writing process is also complicated.
One of my working goals was to be able to use source code management, so I write in plain text files. I have eight years of subversion repositories for my creative writing, and that was part of my goal: I don’t lose anything.
But: Given that I’m leaving the server where I’ve got subversion hosting and can therefore move to anything I want — where to go, what to do?
Also, I think I want to switch to git.
My history with these things:
- A novel is a directory, where the chapter files are named xxx-chap-nn.txt, other necessary files (e.g., a template file with things like author info and pseudonym) are in that same directory, and there’s a support directory with other files (like research notes)
- A short story is a single file in a directory of shorts. Until now, all my shorts were in the same repository (because that worked well with Subversion), but I think that’s the wrong answer.
- When I submit a piece, I create a subversion tag for that submission. So, instantly, I can look at a piece and see what I submitted for a given editor and how it has (or has not) changed since then.
How I get it from text files into the final version: I write in Markdown, render the Markdown into HTML, massage into XML, use XSL-FO with XSLT stylesheets to generate a PDF and RTF. It’s a fidgety process prone to breakage, and I’d actually like to just go straight to RTF/EPUB from HTML.
Dropbox gives me the freedom of a directory structure that iCloud sharing does not, so I could still keep my existing novel structure in Dropbox. That would make it possible to still use Subversion, but I’m not sure how well it’d work with git.
Other people have wondered why I have such a fiddly system. Because some editors still prefer Courier. Some want anything but Courier. (Personally, I’ve grown to like Courier, hate Times New Roman, and generally use Georgia as my “most compatible with everyone” font of choice.) Sometimes you want to print 1-1/2 lines for editing to save gobs of paper. Maybe you want to print a reading copy for someone.
With my old system, I can just use a different XSLT stylesheet. But I could just use something like (or exactly like) PhantomJS to inject a CSS stylesheet and document header information — et voila, HTML with stuff I don’t actually keep in my writing documents.
With MacOS X, I can convert from HTML to RTF easy peasy, so I don’t need the old messiness:
textutil -convert rtf novel-chap-01.html novel-chap-02.html novel-chap-03.html
So the question I have: Git or SVN for this? And why? And where to host (given that I don’t want to share my repositories with anyone)?
Here’s what I do care about and don’t care about:
- I need a fair number of private repositories. 100-ish.
- Don’t need other “developers” (aka writers).
- Space is not a concern. Books are small. Typical hardcover is ~1MB of text.
- SSL would be nice.
- Don’t need issue management or Trac or yada yada.
Looks like CloudForge is the best per this page, but that focuses on SVN hosting (though CloudForge does both). Let’s put it this way: GitHub is too expensive for the number of private repositories I want to have, so it’s a non-starter.
Edited to add: I specifically want offsite repos.
Jun 2006: RailsDay 2006
Well, I missed it (busy doing things I couldn’t move in time), but I thought I’d see who used which plugins for Railsday, just to see if there were any cool new ones.
Here’s the list. (deleted because outdated)
I got it by checking out the source for all the projects and trawling through the vendor/plugins directories.
Aug 2005: Thirty Years of Development
I was asked a few weeks ago how many languages I’ve been paid to develop in during my thirty years as a software engineer and developer.
I’ve excluded database languages and language dialects, but here’s the list, in approximate chronological order:
- Basic (and not that visual kind)
- Fortran
- PL/I
- Assembly
- Pascal
- Ratfor (which, while a preprocessor for Fortran, is much more Algol/Pascal-like than Fortran like, thus listed separately)
- Forth
- Lisp
- Ada
- C
- Hypercard
- Smalltalk
- C++
- Prolog
- Applescript
- awk
- sed
- Perl
- bash
- Objective-C
- Javascript
- Python
- PHP
- tcl
- Java
(After this post, I started developing in Ruby, which remains my primary language.)
May 2005: Ruby on Rails: Thoughts by a Former Python Fanatic
I read some critiques of Ruby on Rails today—and I’m not sure some of the people weren’t just missing some of the point.
Programmers tend to forget how inaccessible programming is. Even seasoned programmers occasionally do the bang-head-against-desk thing while trying to figure out how to overcome the limitations of some new thing.
Ruby on Rails is accessible to many who wouldn’t otherwise learn a web application framework. Even if it isn’t sliced bread (couldn’t say, haven’t learned it), it at least teaches concepts that could be useful.
Ian Bicking had some interesting comments about Python. I’ll admit: even though I love Python, it’s never the first tool I reach for for web work. It’s often the first tool I reach for for other work.
A lot of Pythonistas were never taken with Zope. People learned to love/hate Python because of Zope, but rarely the other way around. I’m one of the people who never twigged on Zope. I gave it only a half-hearted try, granted.
I overcame my initial dislike of Java to learn WebObjects, and I learned (some) XSLT in order to generate PDFs. So, like many, I come to the language as a result of the framework, not the other way around.
One of the other people mentioned Myghty, which I confess I hadn’t heard about before. Even so, none of the examples I perused had any database access (and thus missed the point). Further, this shows exactly the sort of problem I hated with mod_python. Compare the sort of httpd.conf used for Ruby on Rails here.
As far as I’m concerned, Rails is so much more maintainable in that regard it’s not even funny.